The Ever Changing Theories of China and AI
Aug 16, 2023 · 3012 words · 15-minute read
This post is part of a series on China and AI. [Substack version]
- Set-up I: The Ever Changing Theories of China and AI (this one)
- Set-up II: Three Theories of China’s Tech Crackdown (to be posted)
- Set-up III: Understanding U.S.-China Tech Development Through B2B SaaS Investing (to be posted)
- Set-up IV: Why Do American and Chinese Tech Companies Differ in Their Strategic Focus and Work Culture? (to be posted)
- Main: Challenging the “What About China”(WBC) Argument - Bringing in Commercial and Political Incentives (to be posted)
This post reviews the numerous theories put forth in recent years to explain China’s lead or lag in AI compared to the U.S. at different points in time. While I don’t believe any of the theories to be entirely incorrect, their consistent failure to make accurate predictions, coupled with post-hoc introduction of new theories following each technological paradigm shift, underscores the need for greater humility and acknowledgement of epistemic uncertainty when formulating new theory.
Period 1: Pre-2018, Image Recognition / CNNs, China 🚀
The stand-out theories in this period both point to China’s data advantage and predict that China would rival or even overtake the U.S. in “AI.”
- Kai-fu Lee’s 2018 book AI Superpowers (see interviews: FT, Forbes, McKinsey, Baillie Gifford) makes the claim that China could overtake the U.S. in five years. His reasons:
- Stronger, more consistent government support for strategic sectors (e.g. autonomous vehicles)
- Abundant engineering talent
- More data
- More intrusive data collection by firms, due to the population’s lesser privacy concerns and relatively lax government regulation
- Bigger population
- Beraja, Kao, Yang, and Yuchtman’s paper “AI-tocracy” reaches the same conclusion with a different argument: More government demand for surveillance –> more data collection through procurement contracts –> better AI models –> better surveillance. (A similar paper is “Data-Intensive Innovation and the State: Evidence from AI Firms in China” by Beraja, Yang, Yuchtman.)
To be transparent – I had deep skepticisms about the arguments at the time. I remember asking the authors at a seminar what qualitative difference there was between a private U.S. company such as ClearView, which scraped all of social media and worked with the U.S. police and judiciary, and Alibaba/Megvii/Hikvision (the surveillance camera leader with lots of government contracts).1 Wasn’t it possible, if not likely, that the vision models of ClearView, with a much more ethnically diverse dataset, would perform better than those of Hikvision or Megvii? (Ironically, this argument was brought up by a UW CS professor in 2023 as an explanation for why China is lagging behind in AI. More on that below.)
Other metrics researchers used as outcome variables were 1) number of CVPR or other top conference papers authored by researchers with Chinese industry or academic affiliations; 2) valuations of AI companies. On those measures, China was rising rapidly if not outpacing the U.S.
Publication numbers are probably the best metric we have to proxy for distance to the research frontier, so I won’t quibble with the quality issue, though I think it’s important to flag that Chinese firms have much stronger incentives to publish at top conferences relative to their American counterparts because a lot of government subsidy schemes count the number of publications.
Valuations of the four so-called AI dragons / national champions (Megvii, SenseTime, Yitu, Cloudwalk) have since nosedived – they collectively lost $10b between 2019 and 2021. Here I also concede that profits and valuations are mostly reflecting the difficulty of monetization, not technical capability. AI businesses suffer from too many edge cases / limited scalability, too low margins (consulting business model rather than traditional B2B SaaS), sky-high R&D costs (employee compensation, compute, data collection + storage + cleaning + labeling).
Looking back, while I don’t think any of the theories is without its merits, the claim that China will somehow surpass the U.S. in “AI” due to its “data advantage” (either due to the expansive surveillance regime or some proactive government industrial policy) turned out to be vastly premature.
Period 2: 2018 - 2023, Language Models / Transformers, China 🥀
Then came the LLMs, which promise “general intelligence” that will surpass humans on all cognitive questions and have general robotics capabilities. As of August 2023, the community estimated timeline of the arrival of such “AGI” is April 2032.
A quick overview of the current LLM/Transformer technological paradigm:
- 2017: The transformer paper (“Attention is All You Need”) was published;
- 2018: GPT (117m params, 20m tokens) was released;
- 2019: GPT-2 (1.5b params, 9b tokens) was released;
- The rest has been scaling.
The consensus view in the Chinese AI community is that they missed the boat and are at least 2 - 3 years behind (see remarks by the former Huawei CEO, CEO of the second largest search engine, former IMF deputy managing director). The most optimistic prediction is that iFlytek will release a GPT-3.5-level product by the end of this year (2023).2
There were scattered press releases of 1) BAAI (essentially a national lab) releasing a model 10x the size of GPT-3 in 2021; 2) Huawei forming an LLM group in 2020 and building language and vision models, including publishing this impressive Nature paper on weather forecasting.
But two things are very clear:
- The Chinese organizations didn’t start pursuing the LLM path until OpenAI has taken off all the risk with its demonstration of GPT-3.
- To the extent that there were actual products (as opposed to press releases), they focused almost exclusively on enterprise use cases and probably looked very different from the kind of “generally intelligent AI” that firms like OpenAI were pursuing.
The few products we could use as consumers were not impressive at all.
BAAI’s Wudao model, when prompted “Can you tell me more about tutoring classes” in 2023, responded with “Yeah you can sign up for a tutoring class, but you gotta pick one that suits your needs.” ChatGPT (GPT-3.5), on the other hand, wrote an entire essay on the criteria one ought to consider when picking a tutoring class. The ChatGPT language was also a lot more polite and formal, something you could submit to your boss, whereas the WuDao language clearly came from social media and would be too casual in a workplace. (You can make your inferences about the data and the model architecture used in training.)
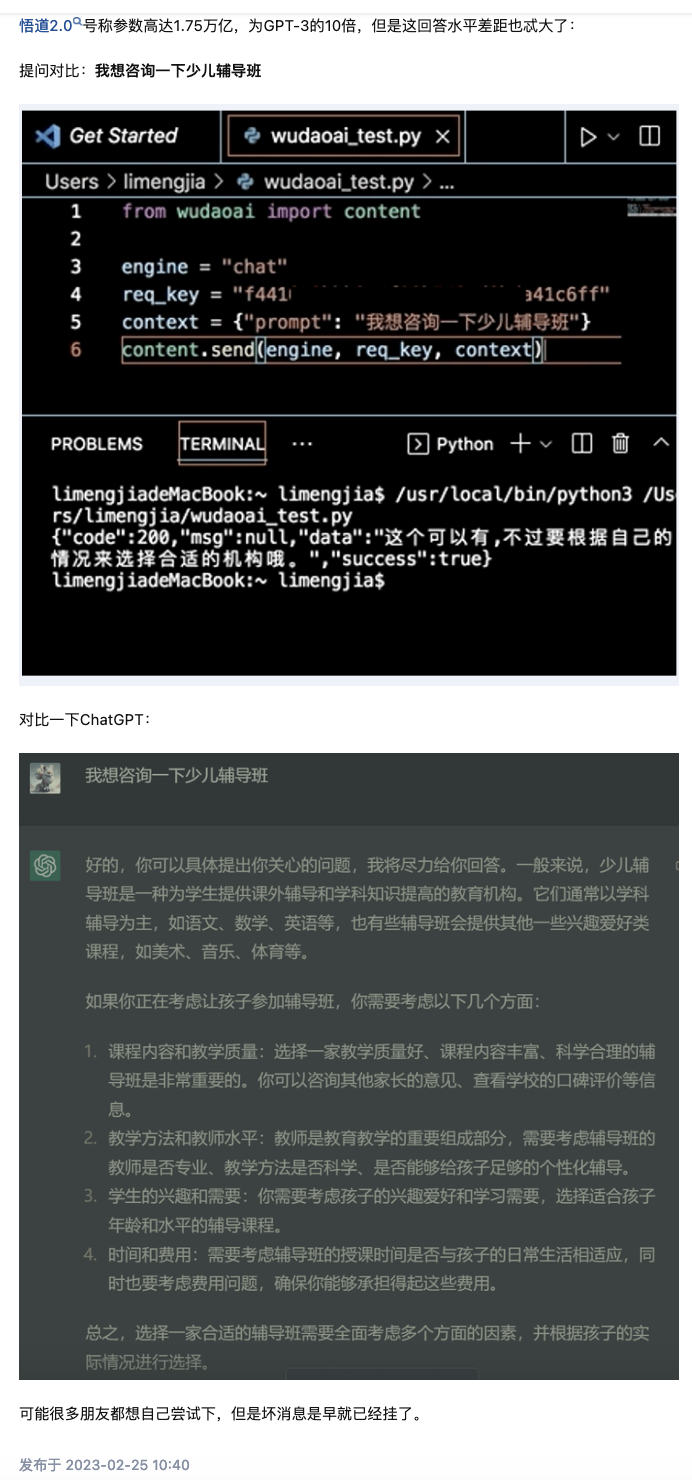
Many theories were floated in the postmortem on why China missed out on LLMs:
-
Lack of data
This theory was brought up the most frequently, although it makes little sense from a technical perspective. From a model architecture perspective, performance should be quite language-agnostic. From an empirical perspective, even though 92% of GPT-3’s training data is in English (by word count), its performance in other languages is also quite good.3 Only a year after the launch of ChatGPT did Chinese models get close to ChatGPT in terms of Chinese-language performance, and even this claim I think would be disputed.4
Assuming this data theory has some truth, different people have put forth different reasons for the lack of data.
One theory, advanced by Yang in his papers “Censorship of Online Encyclopedias: Implications for NLP Models” and “The Digital Dictator’s Dilemma”, would say that Chinese-language text corpora has been so corrupted by censorship that training LLMs on this dataset would amount to solving the distributional shift problem, i.e. it’s extremely difficult to “recover” the underlying “truths” if a lot of what you have online is half-truths or if a lot things never appear on the Internet due to censorship and self-censorship.
Another theory is simply that China is still a developing country, and English is the lingua franca of the world’s elites (academics, businesspeople, etc.). Hence, it wouldn’t be surprising that a Japanese LLM or a Hindi LLM would have less high-quality training data such as academic papers and books in their languages. Anticipating poor model performance, Chinese firms never tried.
My critique of these theories is that if the firms had been properly incentivized, they could have primarily relied on English-language data for pre-training and still achieve solid Chinese-language performance. In fact, that is what the Chinese firms are doing now, after OpenAI has taken off the risk and shown that the transformer architecture can continue to be scaled to reap economic gains.
On the issue of censorship distorting the Chinese corpora – again, if the firms had been truly motivated, they could have used Chinese-language material generated by people outside of China (e.g. the diaspora, Chinese speakers in Southeast Asia). Those populations exceed 50 million, the size of Italy, France, or the U.K. And for the purpose of knowledge-focused LLMs, most of what’s exclusive to the diaspora corpora (political text) perhaps wouldn’t be very useful anyways.
-
The Generative Nature of LLMs
Another theory people have floated is the idea that the generative nature of LLMs posed too much political risks for firms.
I give credence to this theory, but I’d add that there are deeper institutional issues that changed an entrepreneur’s incentives.
Empirically, we do see that a popular AI anime chat product Glow (similar to Character.ai and Inflection’s Pi) was taken off the App Store on the orders of the Cyberspace Administration after gaining 4m users in a number of months in 2023. Reportedly, Glow was powered by one of the best Chinese LLMs Minimax and received strategic investments from one of the most successful Chinese gaming companies miHoYo ($4b revenue in 2022, on par with that of EA and Activision Blizzard).
Risks associated with generative content are only one type of risks LLM/AGI entrepreneurs face in today’s China. Ex-ante (i.e. before OpenAI demonstrated that scaling up LLMs could produce a workable product and possible immediate profit in a year), the cost-benefit analysis a Chinese Altman or Hassabis had to make was whether investing $1m or $10m in a training run – assuming they had access to capital of this scale – would generate sufficient financial returns in 2-3 years in a China-only market5 and be minimally disruptive such that they themselves wouldn’t be at risk.
I have a longer post coming up on the more foundational incentive issues here. My overall assessment is that the data issue explains very little of the limited investment we see ex-ante.
Period 3: 2023 - ?, Scaling Up LLMs, China🚀❓
Now we’re entering a period where the technological path has been demonstrated (i.e. risks borne by OpenAI shareholders), and scaling along this path will surely produce meaningful economic gains and even geopolitical and military ones.
Scaling up requires:
- More compute
- More efficient training (lots of tacit knowledge)
- More and higher quality data
Among these, data is the bottleneck for frontier Western labs, assuming sufficient advanced compute. According to the Chinchilla paper (purely empirical work, not theoretical), data and compute should be scaled in equal proportions, and yet the frontier models haven’t done so with data.
The irony, for people trying to theorize AI, technological development, economic development, geopolitical competition, history, etc., is that we may have entered another period where China will somehow catch up rather quickly and even have an advantage.
I can think of multiple theories predicting another “China advantage”:
- Data advantage
- Lax copyright enforcement: Google, for example, had to remove textbooks from training data due to copyright concerns. It’s also being sued for scraping private information. I can totally imagine a scenario where the Chinese companies or national labs scrape the entire web (Chinese-language and non-Chinese-language), start a massive effort to scan all analog text in an effort similar to Google Books, and are thus able to collect more and higher quality data compared to their Western counterparts.
- Data sharing by law/force: From the economic point of view of purely maximizing total welfare, data is a non-rivalrous good that should be used by as as many firms as possible. The legacy of the U.S.' web-based ecosystem is that most companies build their products on the open web and allow API access to a significant portion of their data. China, on the other hand, jumped directly to mobile where the norm is everyone building their walled gardens. As a result, data sharing between companies, whether in the forms of accessing it via APIs or quietly scraping yourself, has been minimal because the data owner is always reluctant. However, a major development in the post-LLM world is that U.S. firms such as Reddit and Twitter, which produced lots of high quality natural language data, have taken steps to rate limit scrapers. Given that the U.S. government is unlikely to force these companies to share their data, China may again have a data advantage – Chinese LLM regulations (Beijing, Shenzhen) have openly discussed:
- Government coordination of data sharing between firms (just short of open sourcing entire datasets)
- Markets for data exchange (Beijing International Big Data Exchange, Shenzhen Data Exchange)
- Antitrust legislation that could make it illegal for firms to restrict data access to external parties
- Nationalized compute, or central coordination of compute
- Similar to the data advantage above, if the technology has been de-risked (path known, economic gains certain) and all we need is scaling, a nationalized effort or coordination of limited compute resources at some level would again give China an advantage.
- Subsidized or free electricity
- In the most extreme race scenario, it wouldn’t be hard to imagine the Chinese government making electricity cheap or even free for LLM training.
- Engineering talent
- Depending on what your model of AI production is, the tacit knowledge of LLM training that only a few in frontier labs have right now may not be impossible for others to independently arrive at. One data point is that ByteDance (TikTok) is widely regarded as having both more data than competitors and also better engineering – I was told that their recommendation systems had 100x more parameters than Facebook’s. If scaling LLMs is analogous to making content recommendations more addictive, I wouldn’t be surprised if Chinese teams catch up or even exceed U.S. capabilities. The bigger question is whether Chinese engineering talent have the incentive to improve LLM models and whether Chinese firms and national labs create the right environment to retain talent – more on that in a future blog post.
Of course, I’m assuming here that Chinese firms and national labs have access to enough compute – the A800s and H800s NVIDIA supplies to Chinese firms could turn out to be insufficient; the stockpiled advanced chips could run out; those obtained via other channels could run out.
Again, if the game is purely about scaling, Saudi Arabia or the UAE, with no U.S. export controls on advanced compute, a bottomless pocket, and the ability to attract Chinese talent (including those unable to immigrate to the U.S.) – might even be in a better position than China to develop very capable LLMs.
Period 4: ? - ?, New Paradigm (AGI?), China🥀❓
The goals of OpenAI, Anthropic, and DeepMind are general intelligence, not a “better and cheaper AI Customer Service Chatbot.” Hence, while every capable organization in the world is scaling up LLMs in 2023, only the truly ambitious ones will keep taking on risks to test new paradigms in order to build AGI.
When this current mode of scaling reaches its limit (plateauing of compute, exhaustion of human-generated data, etc.), the foundational issues with China’s institutional arrangement will bite. Its commercial actors may be plenty capable, but are they incentivized to build AGI? Its national labs and its military may be plenty incentivized to build, but are they capable themselves or capable of attracting and motivating talent, either the business-oriented Altman types or the science-oriented Hassabis types?
I assign very low probability to these scenarios.6
The larger point I want to make is that the bytes world simply moves too quickly for any social science theory to stick. If you worked on how the invention of gunpowder affected the fall of feudalism, your theory probably withstood the test of time. If you theorized about nuclear proliferation and peace, it may not have been falsified yet. However, if you work on “AI and democracy” (e.g. whether democracies or autocracies are more likely to develop AI, whether AI consolidates autocracy or democracy), your theory necessarily needs major updates every few years because AI is software and software iterates at a much faster pace than any technology humans have built in the atoms world. AI researchers themselves don’t even know the full capabilities of GPT-4 let alone forecast the capabilities of GPT-10 or know its production function / technological paradigm.
We’d live in a far better world if social scientists, rather than making sweeping claims about “AI” and “[regime type]/[rise and fall of nations]/[global balance of power]”, acknowledge the epistemic uncertainty and embrace the fact that anyone’s pet theory lasts two years at best and can only explain, not predict.
-
To be sure, the Chinese and American legal and criminal justice systems work very differently. My point was about firms' access to data and their ability to make good image classification models. ↩︎
-
Other tech executives, including Baidu’s Robin Li and 360’s Zhou Hongyi, made outlandish remarks about their models that have since been proven false. ↩︎
-
Model performance is difficult to evaluate due to intentional and unintentional data leakage, i.e. the inclusion of benchmarks' Q&A text in training. ↩︎
-
Another risk associated with operating in China that few in the AI, China, or social science communities talk about but that is perhaps the first thing mentioned by any entrepreneur is that they have to make so many China-specific adjustments to their products to meet China’s regulations on content, data, etc. such that the cost and time it takes to scale from, say, the China market to the U.S., are a lot higher than from the U.S. to Europe. So most businesses that start out as China businesses remain China-only, whereas if an entrepreneur starts out targeting the U.S., they could easily expand to the rest of the world. ↩︎
-
Interestingly, I think this position puts me in the absolute majority among people who study Chinese politics and economics and the absolute minority among those who follow China in the AI community. (More on forecasting in later posts.) ↩︎